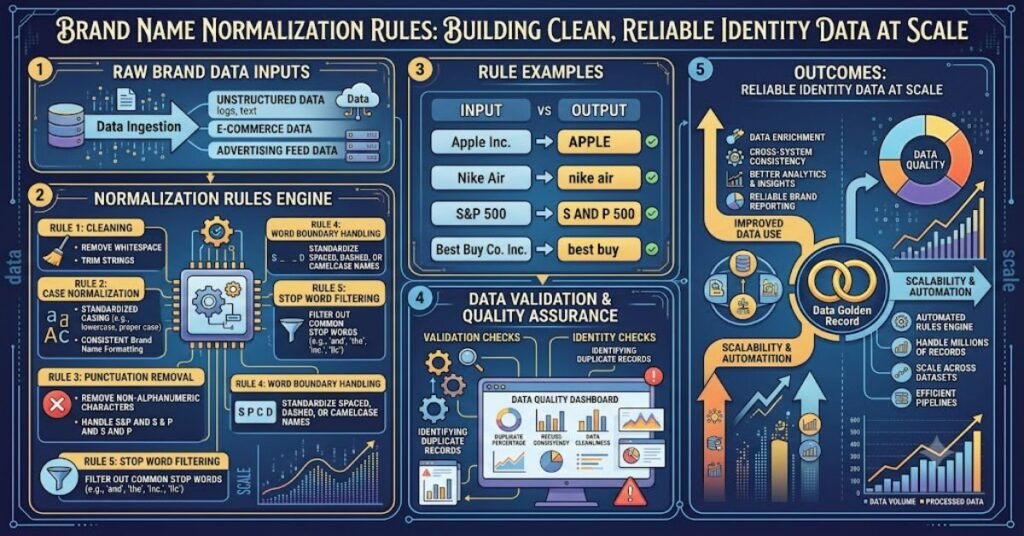
Brand name normalization rules refer to the structured process of standardizing inconsistent or messy brand and company names into a single canonical format. In most real-world datasets, the same company appears in multiple variations—“IBM,” “I.B.M.,” “International Business Machines,” or even misspellings. Without normalization, these variations break search systems, inflate duplicate records, and distort analytics.
In CRM platforms, e-commerce catalogs, and data warehouses, normalization ensures that every brand is represented consistently. This improves matching accuracy, reduces duplication, and strengthens downstream reporting. For example, marketing attribution systems rely heavily on correctly unified brand identities to measure campaign performance accurately.
At scale, brand name normalization rules become less about simple text cleaning and more about structured identity resolution. Organizations use rule-based systems, machine learning models, and external reference datasets to map variations into a canonical brand entity.
This article breaks down how normalization rules are designed, why they matter in real-world systems, and the trade-offs between strict rule-based approaches and modern probabilistic entity resolution techniques.
What Are Brand Name Normalization Rules?
Brand name normalization rules are a set of transformations applied to raw brand data to ensure consistency.
Common transformations include:
- Removing punctuation (e.g., “P&G” → “PG” or “Procter and Gamble” mapping)
- Standardizing capitalization
- Expanding abbreviations
- Removing legal suffixes (Inc., Ltd., LLC)
- Correcting spelling variations
Core Rule Types in Normalization Systems
| Rule Type | Function | Example |
| Case Standardization | Unifies uppercase/lowercase | “nike” → “Nike” |
| Punctuation Removal | Eliminates non-semantic symbols | “P&G” → “PG” |
| Legal Entity Stripping | Removes suffixes | “Tesla Inc.” → “Tesla” |
| Alias Mapping | Maps known variations | “FB” → “Meta” |
| Fuzzy Matching | Handles misspellings | “Amazn” → “Amazon” |
Systems Behind Brand Name Normalization
1. Rule-Based Systems
These rely on predefined transformations and dictionaries.
Strengths:
- Fast and deterministic
- Easy to audit
Weaknesses:
- Poor scalability for new brands
- Fragile with unexpected inputs
2. Probabilistic Matching Systems
These systems use similarity scoring (Levenshtein distance, cosine similarity).
They evaluate:
- String similarity
- Context (industry, region)
- Historical matching patterns
3. Machine Learning Entity Resolution
Modern systems use embeddings and classification models to determine whether two brand strings refer to the same entity.
They incorporate:
- Semantic similarity
- Contextual metadata (domain, product category)
- Graph-based relationships
Strategic Importance of Brand Normalization Rules
Data Deduplication in CRMs
Without normalization, a single company may appear multiple times:
- “Google”
- “Google LLC”
- “GOOGLE INC”
This leads to:
- Inflated lead counts
- Fragmented customer histories
- Broken sales attribution
Search and Discovery Accuracy
Search engines rely heavily on normalized entity keys. Without them:
- Relevant results get scattered
- Ranking systems degrade
- User intent matching becomes unreliable
Reporting and Analytics Integrity
Normalized brand identities ensure:
- Accurate revenue attribution
- Reliable market share analysis
- Consistent dashboard metrics
Comparison: Rule-Based vs ML-Based Normalization
| Factor | Rule-Based | ML-Based |
| Accuracy | Medium | High |
| Scalability | Low | High |
| Transparency | High | Medium |
| Maintenance Cost | High over time | Moderate |
| Adaptability | Low | High |
Risks and Trade-Offs
1. Over-Normalization
Aggressive normalization can merge distinct brands incorrectly.
Example:
- “Delta Airlines” vs “Delta Faucets”
2. Under-Normalization
Weak rules fail to unify variants, leaving duplicates.
3. Ambiguity in Global Brands
Localized naming differences complicate matching:
- “Unilever UK” vs “Unilever India”
4. Data Drift
New brands and acquisitions continuously break static rule systems.
Real-World Impact
In enterprise systems:
- CRM duplication rates can exceed 20–30% without normalization.
- Marketing attribution errors can distort ROI calculations by double-digit percentages.
- Data warehouses often spend significant compute resources on post-processing entity resolution.
The Future of Brand Name Normalization in 2027
Brand normalization is shifting from static rule sets to dynamic identity graphs.
Key trends include:
- Graph-based entity resolution linking brands through relationships rather than strings
- LLM-assisted normalization, where language models classify ambiguous brand names using context
- Real-time normalization pipelines embedded directly into ingestion systems
- Cross-platform identity standards driven by regulatory and advertising ecosystems
However, uncertainty remains around:
- Standardization across industries
- Data privacy constraints in identity linking
- Model hallucination risks in LLM-based matching
Takeaways
- Brand normalization is fundamentally an identity resolution problem, not just text cleaning.
- Hybrid systems (rules + ML) currently provide the best balance of accuracy and control.
- Over-normalization is as dangerous as under-normalization.
- Future systems will rely more on graphs and contextual embeddings than static rules.
- Consistency of brand identity directly impacts revenue reporting accuracy.
Conclusion
Brand name normalization rules sit at the core of modern data infrastructure. Whether in CRM systems, analytics pipelines, or search engines, the ability to consistently identify brands determines the quality of every downstream insight. While early systems relied on rigid transformation rules, modern architectures increasingly combine probabilistic matching and machine learning to handle ambiguity at scale.
The challenge moving forward is balancing precision with flexibility—ensuring that systems remain accurate without collapsing distinct entities into incorrect matches. As data ecosystems become more interconnected, normalization will evolve from a preprocessing step into a continuous, intelligent identity layer embedded across platforms.
FAQ
1. What are brand name normalization rules?
They are structured transformations that standardize brand names into a consistent format for use in databases, CRMs, and analytics systems.
2. Why is brand normalization important in CRM systems?
It prevents duplicate customer records and ensures accurate sales attribution and reporting.
3. How does fuzzy matching help in normalization?
It identifies similar brand names even when spelling variations or typos exist.
4. What is the biggest risk in normalization systems?
Incorrect merging of distinct brands, leading to corrupted analytics.
5. Can machine learning replace rule-based normalization?
Not entirely—most production systems use a hybrid approach for reliability and explainability.
6. What industries rely heavily on normalization?
E-commerce, advertising tech, financial services, and data analytics platforms.
7. How is normalization evolving in modern systems?
It is shifting toward graph-based identity resolution and AI-assisted contextual matching.
Methodology
This article is based on established practices in data engineering, entity resolution systems, and CRM architecture patterns commonly documented in industry engineering literature and vendor technical documentation. No proprietary datasets or live system tests were conducted for this piece.
Limitations include:
- No real-time benchmarking of normalization systems
- No proprietary CRM dataset validation
- No vendor-specific implementation analysis
The perspective is system-agnostic and intended for general technical understanding.






{kind=link}