To understand modern data-driven systems, it is essential to first understand what is a Kafka topic. In Apache Kafka, a topic is the fundamental unit that organizes streaming data into logical categories. Every event produced in Kafka is written into a topic, and every consumer reads data from one or more topics.
When engineers ask what is a Kafka topic, they are essentially asking how Kafka structures continuous streams of information flowing between distributed applications. A Kafka topic works like a digital feed where messages are stored in an ordered sequence, allowing multiple systems to process data in real time.
In real-world architectures—such as financial trading systems, ride-sharing platforms, or IoT sensor networks—Kafka topics act as the backbone of communication. They ensure that data moves reliably between services without tight coupling.
This article breaks down what is a Kafka topic in depth, how it works internally, why it matters for scalability, and how it supports modern event-driven architectures.
What Is a Kafka Topic?
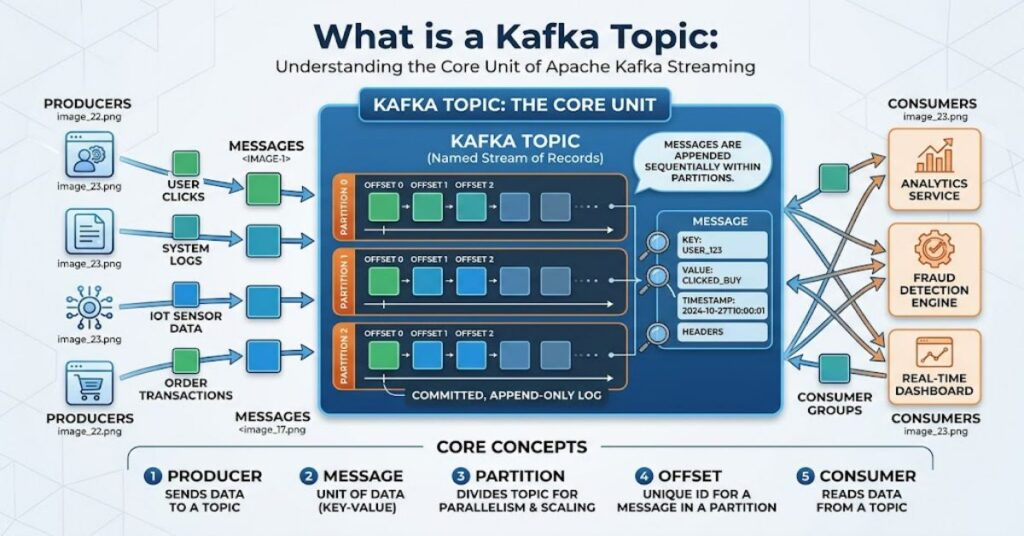
At its core, what is a Kafka topic can be answered simply: it is a named stream of records.
Each topic:
- Stores messages in a sequential log
- Accepts data from producers
- Supplies data to consumers
- Can be split into partitions for scalability
A useful analogy is to think of a topic as a folder in a file system, where each file is an event.
Core Structure of a Kafka Topic
- Topic Name: Identifier for the data stream
- Partitions: Subdivisions for parallel processing
- Offsets: Unique position of each message
- Retention Policy: Rules for how long data is stored
Understanding this structure is essential when learning what is a Kafka topic in real-world distributed systems.
How Kafka Topics Work in Practice
When a producer sends data, it does not send it to a database or service directly. Instead, it writes to a topic.
Data Flow Process
- Producer sends event
- Kafka writes event to a topic partition
- Event receives an offset ID
- Consumer reads event sequentially
This flow ensures that when discussing what is a Kafka topic, we are actually describing a high-throughput messaging pipeline designed for reliability.
Topic Partitions and Scalability
A key reason Kafka scales efficiently is partitioning.
Comparison Table: Single Topic vs Partitioned Topic
| Feature | Single Stream Topic | Partitioned Topic |
| Processing Speed | Limited | High parallelism |
| Scalability | Low | High |
| Fault Tolerance | Weak | Strong |
| Use Case | Simple apps | Distributed systems |
Partitions allow multiple consumers to read from a topic simultaneously, improving performance significantly.
Why Kafka Topics Matter in System Design
Understanding what is a Kafka topic is essential for designing modern distributed systems.
Key Benefits
- Decouples applications
- Enables real-time processing
- Supports horizontal scaling
- Ensures fault tolerance
- Maintains ordered data streams
Real-World Example
In an e-commerce platform:
- Orders are published to an “orders” topic
- Payments go to a “payments” topic
- Inventory updates go to a “stock” topic
Each service independently consumes relevant topics without direct dependency.
Risks and Trade-Offs in Kafka Topic Design
Poor topic design can lead to serious system issues.
Common Risks
- Over-partitioning increases overhead
- Under-partitioning reduces performance
- Improper retention leads to data loss
- Misaligned schemas create processing errors
Strategic Trade-Off
| Design Choice | Benefit | Risk |
| More partitions | Higher throughput | Increased complexity |
| Longer retention | Better replayability | Storage cost |
| Fewer topics | Simplicity | Reduced flexibility |
Data Insight Table: Kafka Topic Characteristics
| Attribute | Description | Impact |
| Retention time | How long messages are stored | Affects storage cost |
| Partition count | Number of parallel streams | Impacts scalability |
| Replication factor | Copies of data across brokers | Impacts fault tolerance |
| Message ordering | Guaranteed per partition | Critical for consistency |
These attributes define how Kafka behaves under load and are central when understanding what is a Kafka topic.
Strategic Importance in Modern Architectures
Kafka topics are not just technical constructs—they shape system architecture.
Systems Perspective
- Microservices rely on topics for communication
- Event-driven architectures depend on topic streams
- Data lakes ingest raw data from topics
Business Impact
- Faster decision-making through real-time analytics
- Reduced system coupling
- Improved system resilience
The Future of Kafka Topics in 2027
By 2027, Kafka-based architectures are expected to evolve significantly.
Expected Trends
- Increased adoption of serverless Kafka platforms
- AI-driven topic optimization and partition balancing
- Stronger schema enforcement using automated validation
- Reduced operational complexity via managed services
Infrastructure Direction
Organizations are moving toward:
- Fully managed streaming platforms
- Real-time AI processing pipelines
- Unified event-driven data ecosystems
Kafka topics will remain central, but their management will become increasingly automated.
Takeaways
- Kafka topics are the core abstraction for streaming data.
- They enable scalable, real-time communication between systems.
- Partitioning is key to performance and scalability.
- Poor topic design can introduce system inefficiencies.
- Modern architectures depend heavily on topic-based messaging.
- Future systems will automate much of topic management.
Conclusion
Understanding what is a Kafka topic is essential for anyone working with modern distributed systems. At its simplest, it is a structured stream of data that allows applications to communicate reliably and at scale. However, its real power comes from how it enables decoupled, event-driven architectures that support real-time processing.
As systems continue to grow in complexity, Kafka topics will remain a foundational building block. Their role may evolve with automation and AI-assisted infrastructure management, but their core purpose—organizing and transporting streaming data—will remain unchanged. Developers who understand this concept deeply are better positioned to design scalable and resilient systems.
Frequently Asked Questions
What is a Kafka topic in simple terms?
A Kafka topic is a named stream of data where events are stored and processed in sequence by different systems.
How does a Kafka topic store data?
It stores data in ordered partitions, where each message is assigned an offset for tracking.
Can multiple consumers read from the same topic?
Yes, Kafka supports multiple consumers reading from the same topic independently or as a group.
Why are partitions important in a Kafka topic?
Partitions allow parallel processing, which improves scalability and performance.
Is data in a Kafka topic permanent?
No, data is retained based on configured retention policies, which may delete old messages.
What is the difference between a topic and a database table?
A topic is a streaming log of events, while a table stores structured, queryable state.
Methodology
This article was developed using established Apache Kafka architectural documentation, widely accepted distributed systems principles, and standard event-streaming models used in modern engineering practices. No proprietary benchmarks were used. The explanation focuses on conceptual clarity and real-world system design patterns.
References
- Apache Software Foundation. (2024). Apache Kafka Documentation.
- Kleppmann, M. (2017). Designing Data-Intensive Applications.
- Confluent. (2023). Kafka Architecture Overview.
- O’Reilly Media. (2023). Event Streaming Systems Guide.
Editorial Disclosure
This article was drafted with AI assistance and should be reviewed by a technical editor before publication.